AI Search analytics is shifting from deterministic metrics (rankings, clicks) to probabilistic metrics (visibility, citations).
Tracking is fragmented, with some signals being observable, some inferable, and some remaining non-trackable.
The core problems are restricted access to query logs and the fundamentally different nature of prompt-based search compared to traditional, keyword-based search.
Tracking tools and methods are flawed, relying on extrapolation and inference, due to the unavailability of real data.
AI search performance analytics will have to rely on triangulated attribution models, correlating spikes in direct traffic with AI-aligned landing pages and qualitative data.
TL;DR: AI answers became a regular and major part of discovery, but AI search analytics tools and methods are still immature. Unavailability of query logs, complex nature of prompts, intention mismatch, and flawed estimation methods remain the biggest obstacles to accurate tracking. By the end of 2026, more standardized measurement primitives may emerge, but marketers will likely have to continue using combined methods to track performance with sufficient accuracy.
AI tools are advancing at a head-spinning rate, solidifying themselves as the new “normal” way of discovery. While users are definitely at an advantage, being able to define their searches to the smallest details, the same cannot be said for brands and their strategists.
The reason is that AI search visibility and performance analytics keep lagging behind, primarily due to the LLM providers’ “black box” policy regarding user-level demand data and the current tools’ inability to accurately measure how, why, and where brands appear within AI answers.
Fortunately, not all is “doom and gloom.” Experienced generative engine optimization services can still measure a lot of data while inferring the rest with significant accuracy – and the evidence suggests that we could see some welcome changes in AI search analytics by the end of 2026.
What can we actually track in AI search right now?
In AI search today, we can directly measure some signals and estimate others, but certain aspects remain unobservable due to platform privacy and the personalized nature of LLM usage. Based on trackability, we can split metrics into three categories:
Trackable (via hard data and synthetic simulations): brand mentions in select prompts, citations, traffic from AI platforms, sentiment;
Partially trackable (via blended data, proxy, and inference): Google AI Mode performance, AI-influenced clicks & sessions, “dark” AI traffic (direct), AI-assisted conversions, brand search lift;
Non-trackable (no data or severe limitations imposed by platform privacy/architecture): Real user prompt volume/demand, zero-click visibility, personalized/contextual user experiences.
1. Trackable metrics
Data can be accurately measured using currently available analytics platforms.
Metric
Method / Tools
Pitfalls / Obstacles
Brand mentions / Share of Voice
Tools: GEO tools (Ahrefs Brand Radar, Peec.ai, Profound AI, etc.) Method: Running a select number of synthetic prompts & calculating the percentage of times the brand appears in AI-generated answers.
Synthetic data (simulated; not from real user chats) Missing personalization data (e.g., user history, location, context, etc.) Sample size (probabilistic nature of the data renders small sample sizes statistically insignificant).
Citation presence/frequency
Tools: GEO Tools Method: Scraping AI outputs to see whether a specific URL/domain is cited as a source.
Volatility (citations can change/disappear between runs) Presence is unstable/probabilistic. Limited data due to the simulated nature of the tracked prompts
Referral traffic from AI platforms
Tools: Google Analytics 4 (GA4) Method: Using Regex to filter by “Session Source” for chatgpt.com, perplexity.ai, gemini.google.com, and copilot.microsoft.com
Referrer stripping (many AI apps strip referrer headers; traffic appears as “direct”, instead of “referred”) Inconsistency (traffic sources vary between mobile and desktop apps) Traffic to promptmatching remains limited.
Tone / Sentiment
Tools: GEO Tools Method: Analyzing the text surrounding the brand mentions & classifying the tone as “Positive”, “Neutral”, or “Negative”.
Hallucination Risk (AI providing incorrect info, e.g., pricing or features, leading to high but harmful visibility). “Dark” sentiment (inability to track sentiment outside of pre-selected prompts)
2. Partially trackable metrics
Metrics are blended with other data or require inference/deduction.
Qualitative methods only (post-conversion surveys, user feedback, interviews, self-reported attribution)
Invisible to analytics: If a user reads about a brand in an AI answer, but does not click, this leaves no footprint in analytics software.
Personalized/contextual user experiences
None. Tools can only simulate “neutral” or “fresh” (non-personalized) sessions.
Context windows: AI-generated answers change depending on the user’s chat history, context, and location. Results cannot be replicated or observed.
Why is there no real “search volume” for AI prompts?
Due to AI platforms’ privacy policies, as well as the nature of prompting being fundamentally different from traditional keyword-based search, the majority of AI search volume and performance analytics rely on theoretical estimates. While that’s about it in a nutshell, the real issue goes much deeper.
1. The core problem: “Black Box” data policy
The first and arguably the largest obstacle is restricted access to key data necessary for definitive search volume measurement: query logs. This problem is three-pronged:
LLM providers (OpenAI, Anthropic, Google) consider query logs a corporate advantage, treating them as proprietary and hiding them behind a privacy shield.
As of now, there are no APIs that can report how many times users asked answer engines a specific question or typed a specific phrase.
Most AI platforms do not run ads, so there’s no incentive to publish query demand data.
Consequently, any “AI Search Volume” produced by third-party tools is only a guess, based on extrapolation rather than being grounded in real user data.
However, with sponsored content officially coming to ChatGPT, there is a reasonable probability that OpenAI will start releasing real search volume data to advertisers to help them bid on ads, but that remains speculative for now.
2. The “Long-Tail” Problem
As mentioned above, prompt-based search dramatically differs from traditional search, specifically across three modes:
Prompts are conversational, often consisting of full sentences or paragraphs (i.e., 10 – 25+ words) – not short, repeatable keywords.
Result: Prompt strings are NOT stable units.
Prompts are personalized, with two users rarely typing exactly the same phrase, even if they’re searching for the exact same product/service.
Result: Virtually infinite number of variations, especially considering the enormous user base.
Prompts are often iterative, with users refining their search multiple times per a single session.
Result: A single prompt can branch into multiple intents.
Therefore, even if query logs were available, AI prompting still wouldn’t aggregate cleanly into traditional volume metrics. In other words, AI search analytics must rely on different metrics and methods to deliver accurate results (e.g., tracking Share of Voice, citation presence, sentiment across a topic, etc.)
3. The “Intent Mismatch”
In direct contrast to traditional search, the majority of queries in AI environments do not signal intent. If we observe how people are using ChatGPT, Perplexity, or any other LLM, we can see that a significant portion of prompts is utility-based rather than exploratory. Counting these prompts toward volume would only result in overinflated data, not only irrelevant to AI search visibility analytics – but actually undermining it.
4. Flawed estimation methods
Since the real data (i.e., query logs) are locked behind privacy shields, third-party tools rely on imperfect proxies to “guess” the volume. The danger of these results is that they may look precise when they’re actually based on extrapolation and estimation. While it’s far from useless, this “pseudo-accuracy” is directional at best, meaning it can and often is misleading in AI search performance analytics if taken at face value.
Stay Ahead of AI Search Developments
Sign up to The Laboratory and get the latest GEO insights, AI optimization strategies, and expert tips straight to your inbox.
What will AI search analytics look like by the end of 2026?
Based on how the AI search analytics has been evolving since 2024, as well as the industry trends and available data, we can make educated guesses as to how the methodology may shift by the end of 2026.
Potential new standards in AI search analytics
These are high-confidence scenarios, most likely to define AI search performance and visibility analytics in 2026, as they’re based on current documentation, tool capabilities, and LLMs’ architectures:
“Rank” becomes obsolete/is no longer enough: The highly variable, user-centric nature of AI-generated answers, “Ranking” may be pushed to the background in favor of Citation Score or Share of Voice.
The “Black Box” remains: AI platforms currently have no incentive to share query logs, so marketers, strategists, and analysts will most likely continue to rely on directional third-party estimates.
Triangulated attribution models: Due to AI traffic often appearing as “direct”, AI performance analytics will have to rely on correlating spikes in direct traffic with AI-specific landing pages and qualitative data.
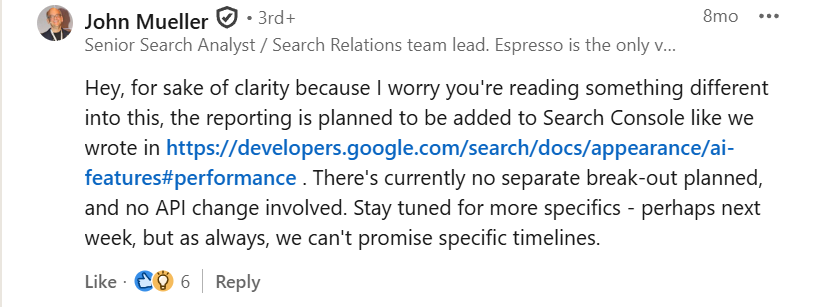
GSC remains opaque: Google’s John Mueller confirmed that “There’s currently no separate break-out planned” for AI traffic, meaning they’ll likely continue to blend AI Mode data with organic results.
LinkedIn post confirming Google isn’t planning a separate break-out for AI Mode reporting in GA4
The “Tipping Points”
Due to heavy dependence on factors such as regulatory pressure, competitive shifts, or platform policy reversals, these scenarios have a reasonable chance (i.e., ~50/50) of becoming new standards in AI search analytics:
Google introduces an AI filter into GSC: The fact is that more and more B2B buyers are turning to AI in everyday operations. So, even though this is not currently planned, the pressure from publishers losing visibility to zero-click answers could force Google to change its tune and offer transparency.
Standardized “AI Referrer” headers: The rising popularity of agentic shopping prompted Google to create a Universal Commerce Protocol. Given the even higher prevalence of AI-assisted searches, it’s not a stretch to assume that we may see a standardized protocol where AI agents consistently identify themselves in server logs.
Sentiment Analysis as a standardized KPI: LLMs can still cite the brand negatively or incorrectly, effectively turning high visibility into a downside. This fact could drive AI visibility dashboards to standardize Sentiment Scoring alongside visibility tracking, enabling for automatic flagging of brand mentions of positive, neutral, negative – or factually incorrect.
LLM companies provide actual volume metrics based on user data: With ads already implemented in Gemini, Perplexity, and soon in ChatGPT, the AI platforms will likely become CPC battlegrounds, with brands fighting tooth and nail to be the ones featured in a very limited space. This may not be enough to drive LLM providers to break the black box, but it might be enough to nudge them to make it a bit more transparent.
Lily Evans is the Managing Director at ZeroClick Labs, bringing over 8 years of comprehensive experience in SEO, local SEO, and AI optimization to every project. She began her career in content writing, developing a strong sense for search intent and messaging clarity in the digital realm – skills that form an unshakable core of her leadership to this day.
The current state of AI search analytics is painted with the odds and obstacles, restrictive policies and privacy shields, and data “black boxes” and tool imperfections. Does that mean brands are deprived of reliable methods for tracking visibility and performance within AI platforms? Absolutely not!
High-tier AI SEO companies – such as ZeroClick Labs – adapt to the shift by engineering new, hybrid methodologies that enable them to track relevant metrics, whether they be deterministic or probabilistic.
So, despite the landscape changing and the discovery environment being more volatile than ever, success is not only possible – but can be made probable.
“Our agency had no idea how to approach AI visibility. ZeroClick only does this one thing so they actually know what works. Worth every penny just to not waste time figuring it out ourselves.” – Jay