ChatGPT cites from two layers: live retrieval you can shape now, and trained memory you build through sustained authoritative presence.
Crawl eligibility is the precondition to rank in ChatGPT search – if OpenAI bots cannot reach you, content quality and optimization level are irrelevant.
Query fanout and RRF reward consistent, multi-angle topical coverage over top rankings and focused hyperoptimization.
Product and service pages are ChatGPT’s preferred format, with listicles a close second.
Your reputation is assembled on- and off-site, requiring optimization of the internet consensus about your brand, not just your own domain.
Executive Summary: ChatGPT has become one of the primary research and decision-making surfaces for buyers, and being named in its answer is now a distinct commercial objective. The model cites from two distinct layers: trained memory and live retrieval, both of which respond to optimization, but on different timelines. Winning visibility starts with crawl eligibility, then compounds through answer-first, extractable content, full-arc coverage, and off-site third-party corroboration.
As of June 2026, ChatGPT boasts 1billion monthly active users. Every day, they send 2.5 billion queries, roughly 20% (500 million) of which have commercial intent. To answer those queries, ChatGPT performs a series of research, comparison, and shortlisting, and it does most of it behind the scenes. The user only sees the endpoint: a synthesized, actionable answer.
For most, that’s more than enough.
Users are increasingly ready to act on the synthesized answer alone, without visiting a single website, which means that the brands named inside the answer capture the intent. Everyone else? Invisible. With buyers starting their journey deep in the decision arc, not at the top of the funnel, the search dynamic has shifted forever, and so have the optimization goals:
The click is no longer the prize. The recommendation is.
Disclaimer: This is deliberately not a technical manual on how to do SEO for ChatGPT. Rather, it is built to explain how ChatGPT selects and cites content, and why current ChatGPT SEO practices work, giving marketing leaders and business owners a strategic, directional understanding of the zero-click visibility model.
How does ChatGPT choose what to cite?
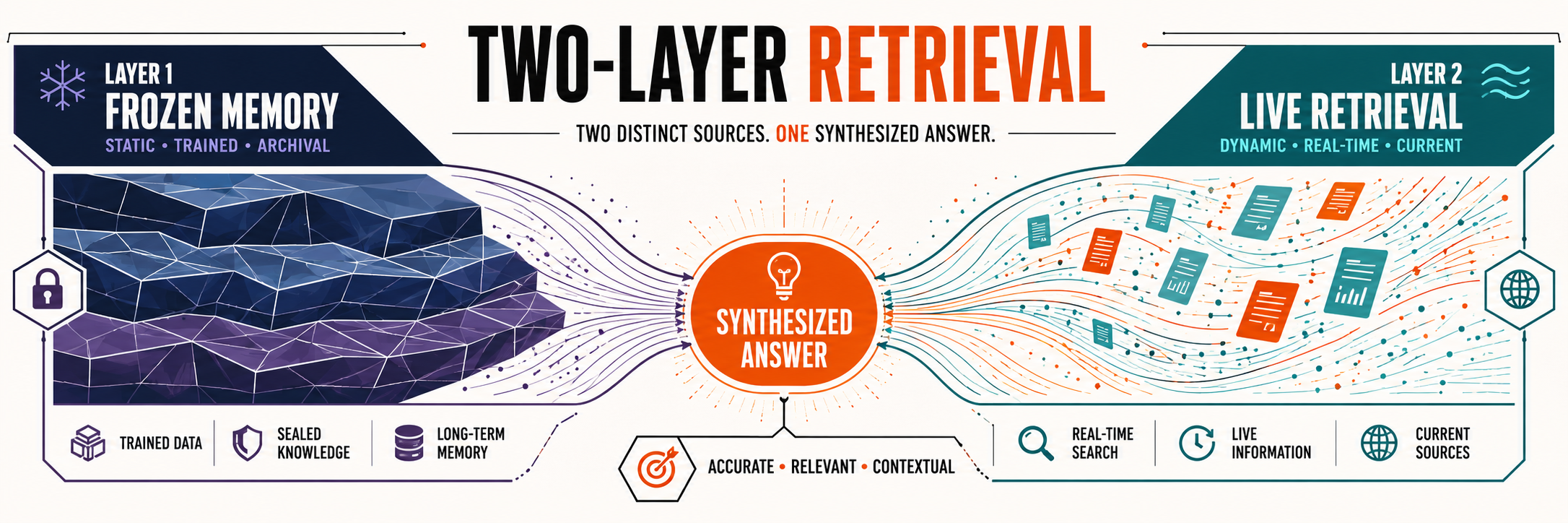
Before we get to figuring out how to rank in ChatGPT, it’s crucial to understand the model’s citation selection mechanism. ChatGPT relies on two distinct layers: a static training layer (pre-cutoff) and a live retrieval layer (RAG). Knowing which layer you’re optimizing for is the core of ChatGPT SEO, and the foundation for everything that follows.
ChatGPT answers from two layers: trained memory and live web. [Image credit: ZeroClick Labs via ChatGPT]
The static training layer
The training layer represents everything the model learned before its knowledge cutoff. Brands that appeared frequently and authoritatively across the web up until that point are the ones ChatGPT associates with a topic by default.
The training layer cannot be influenced retroactively, meaning that brands need a high volume of authoritative mentions to “survive” the cycle, which brings us to the first critical insight on how to optimize for ChatGPT:
Consistent presence today is what shapes the NEXT training cycle and future citation selectability
The live retrieval layer
For real-time (“live”) queries, ChatGPT switches to Retrieval-Augmented Generation (RAG). Without getting technical, the most important thing to understand about RAG pipelines is that they reward fundamentally different things from traditional search mechanics:
Instead of keyword density, RAG rewards information density.
Furthermore, Google’s notes align with the foundational academic framework for the entire AI SEO industry, Princeton’s KDD 2024 study, which showed that keyword stuffing is actually counterproductive to AI search visibility.
+115%Source citations — the “equalizer.” Adding citations lifted visibility of a low-ranked (position-5) source by up to 115%.
Hover or focus a bar for why it worksSource: Princeton GEO study, KDD 2024
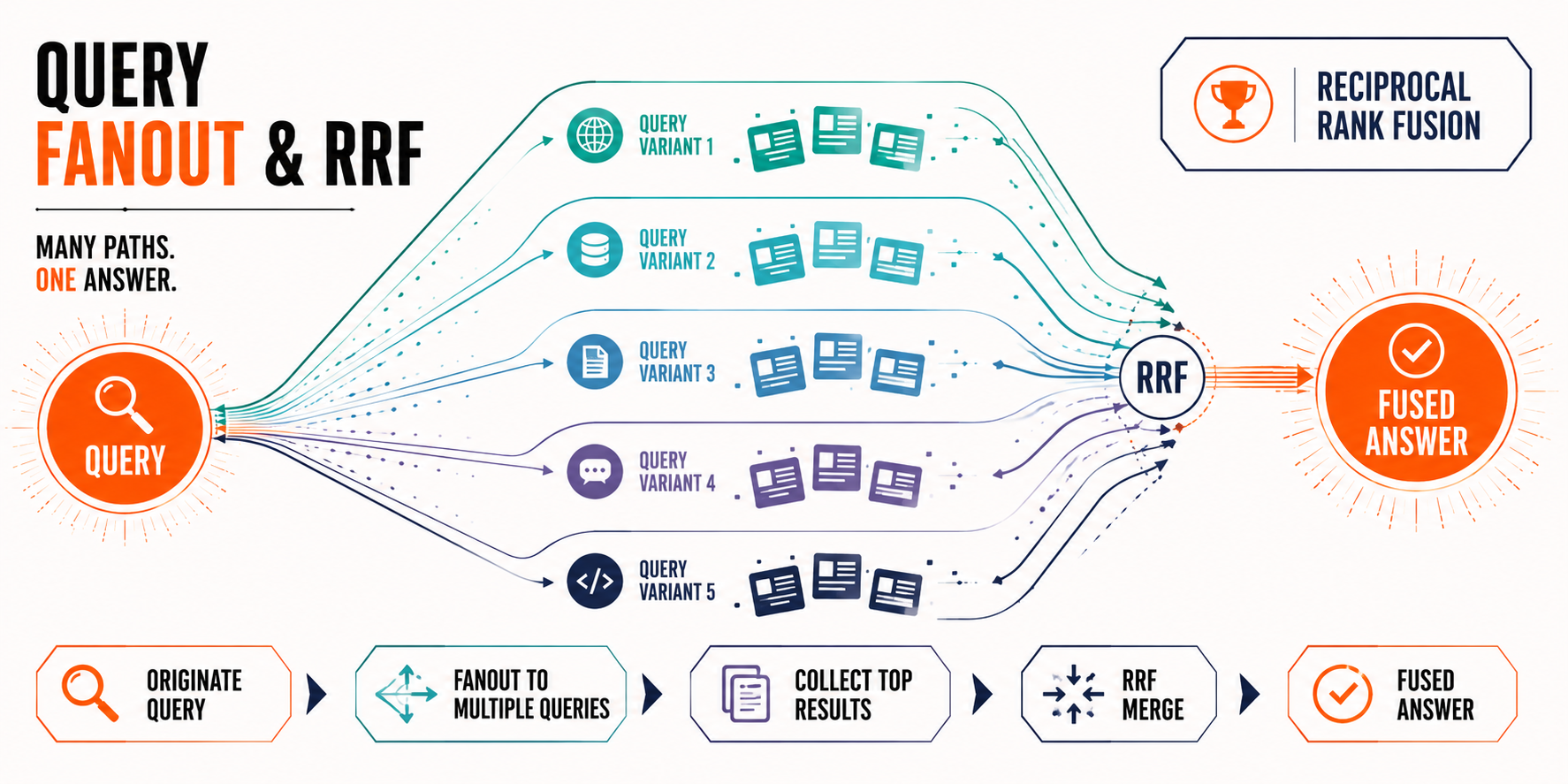
Query fanout & Reciprocal Rank Fusion (RRF)
ChatGPT rarely searches the exact string the user types. What it actually does is perform a query fanout: it breaks the original prompt down into 2 to 5 distinct sub-queries, applies intent modifiers (e.g., best, vs, 2026, reviews), and performs multiple parallel searches covering different angles.
Then, it uses Reciprocal Rank Fusion (RRF) to score, rank, and ultimately, merge the results into a single ranked set behind a single synthesized answer. Here’s the key catch: because the RRF equation sums the scores across all parallel query lists, pages that appear consistently across multiple sub-searches are the ones selected for the final synthesis.
This mechanic is the beating heart of how to rank in ChatGPT search: consistent presence across as many sub-queries as possible – not a cemented #1 position for the exact-match initial query.
Query fanout & RRF: One prompt expands into several sub-queries, then merges into a final cited answer. [Image credit: ZeroClick Labs via ChatGPT]
What ChatGPT weighs at the moment of synthesis
When ChatGPT decides which retrieved sources to cite, three criteria do the majority of the work:
Authority: Genuine expertise signalled through original research and consistent topical coverage, corroborated by credible third-party sources. Domain authority still matters, but it’s superseded by topical depth.
Entity clarity: An unambiguous, consistent answer to who the brand is, what it does, and who it serves. If those signals conflict across the web, the model tends to skip the brand regardless of content quality.
Extractability: Content’s ability to be lifted by a model cleanly, without interpretation. The more “effort” ChatGPT has to expend to parse the content, the less extractable it becomes.
The above three signals overlap with traditional SEO authority, but ChatGPT applies them far more heavily, and at the point of synthesis rather than ranking. Consequently, they are the primary AI citation levers and the foundational answer to how to rank in ChatGPT.
At the moment of synthesis
The three levers behind every citation
Applied harder than in classic SEO — and at synthesis, not ranking.
Authority
Original research and topical depth, corroborated by credible third parties.
Entity clarity
A consistent answer to who you are, what you do, who you serve.
Extractability
Content a model can lift cleanly, with no interpretation needed.
Hover or focus each box for detailSource: ZeroClick Labs
Stay in the Loop – Stay Ahead
Sign up for The Laboratory newsletter and get the latest insights from AI world straight to you inbox!
How to optimize for ChatGPT Search?
You’ll have to approach optimization from two sides simultaneously: the technical layer (bot access) and the content layer (native and off-site).
How to optimize a website for ChatGPT?
From a technical optimization standpoint, the critical objective is ensuring ChatGPT can crawl your website. This is the precondition for every other facet of ChatGPT SEO and also the point at which a surprising number of brands unintentionally opt out of visibility on ChatGPT. The logic is simple:
If AI can’t find you, the quality of your content is irrelevant.
How do you make sure ChatGPT can crawl your website?
Unlike Googlebot, which uses a massive, highly expensive Web Rendering Service (WRS) to crawl the web at scale, OpenAI’s bots operate on a far leaner computational budget, struggle with JavaScript-dependent content, and skip pages that respond slowly or block access. Addressing these three bottlenecks is key to ensuring ChatGPT crawlability.
OAI-SearchBot determines whether you can even appear in ChatGPT search.
GPTBot controls whether your data is used in model training.
ChatGPT-User fetches pages on a user’s direct request.
Blocking these bots can cause complete ChatGPT Search invisibility, and is typically a result of:
Blinding OAI-SearchBot by blocking it wholesale via robots.txt (which is a common enterprise default);
Misconfiguring Web Application Firewalls (WAFs), causing them to flag crawling as suspicious traffic and return 429 (Too Many Requests) or 403 (Forbidden) errors, effectively locking bots out, even though the site looks open on paper.
Practical application: Audit your robots.txt to ensure OAI-SearchBot is allowed, as well as WAF or rate-limit rules that might be throttling or blocking OpenAI crawlers.
Bot access
What blocking each OpenAI bot actually does
Three bots, three different jobs — block the wrong one and you vanish.
Bot
Its job
If blocked in robots.txt
OAI-SearchBot
Gateway to ChatGPT search
Complete AI Search invisibility. Content can’t be summarized or snippeted in live answers.
GPTBot
Training-data inclusion
No real-time impact; affects the static training layer. Safe to block to keep your IP out of training.
ChatGPT-User
Fetches a page on a user’s direct request
No real-time impact (user-triggered). The user sees an error that the link is restricted.
Audit checklistSource: OpenAI bot documentation
Narrow the JavaScript rendering gap
This is arguably the most critical technical bottleneck for modern websites: AI crawlers’ inability to execute JavaScript. ChatGPT is not an exception – OAI-SearchBot and GPTBot simply grab the raw server-side HTML, parse the text, and move on.
If your pricing table, product specs, key claims, or any other piece of critical information is locked behind client-side JavaScript, you can be nearly 100% certain that crawlers will see an empty box – and promptly ignore it.
Practical application: Make critical data available as static HTML.
This happens due to ChatGPT being prone to pattern-based hallucinations. If it wants to cite your brand for “ChatGPT SEO”, it will often “guess” a logical URL structure (e.g., [yourbrand.com/chatgpt-seo](https://yourbrand.com/chatgpt-seo)).
If your server fails to issue a proper 301 redirect to a live page, that citation is instantly killed. What’s more, since ChatGPT retains and revisits URLs over time, every broken legacy link is effectively a citation forfeited.
Practical application: Proactive 301 wildcard mapping is required – catch the guessed URLs and redirect them to live pages.
Technical summary
What changes from traditional SEO
For webmasters: the four shifts that decide crawl eligibility.
Element
Traditional SEO
ChatGPT SEO
JavaScript rendering
Google eventually renders client-side JS.
Fails completely. Core content must ship in raw HTML.
Crawler target
Optimize primarily for Googlebot.
Separate OAI-SearchBot (search) from GPTBot (training).
Firewall (WAF) rules
Google IPs are broadly whitelisted.
AI crawler IPs trip rate limits (429) — need bypass rules.
In general, four optimization tactics will determine whether and to what extent your content is citable: Answer-first architecture, machine readability, full decision-arc coverage, and third-party validation.
All four are derived directly from how grounding (RAG) and synthesis (fanout + RRF) work, meaning that the basic optimization principles can be used for AI Overviews, Perplexity, and other LLMs – not just ChatGPT.
Content optimization
The four levers of citable content
All derived from how grounding (RAG) and synthesis (fanout + RRF) work.
01
Answer-first architecture
Resolve the query in the first 50–100 words. Beat “lost in the middle.”
02
Machine readability
Self-contained, modular chunks a model can extract without guesswork.
03
Full decision-arc coverage
Clusters across the whole journey to win more fanout sub-queries.
04
Third-party validation
Off-site consensus turns your claims into corroborated evidence.
Hover or focus a pillar for detailSource: ZeroClick Labs
Answer-first architecture
ChatGPT suffers from an architecture flaw known as “Lost in the Middle”: a “condition” that makes it highly attuned to information at the very top or bottom of the prompt context, but virtually blind to the middle. This is why RAG retrieval loops penalize buried text and why 44.2% of all AI citations come from the first 30% of a page.
Practical application: State the answer or the conclusion within the first 50-100 words of a section or article, then proceed with the elaboration or contextualization. This is known as the BLUF (Bottom Line Up Front) model, and it’s slowly becoming a standard in AI SEO, precisely because of how RAG works.
Front-load the substance, back with the context. Not the other way around.
Machine-readability
RAG systems do not read entire pages or articles. Instead, they read text chunks (content blocks), typically 100-300 words at a time. When these content blocks are structured for extraction, rather than persuasion (i.e., marketing fluff), you’re creating self-contained, modular semantic units with high fact density.
ChatGPT loves these units for several reasons: they allow it to pull a chunk that directly resolves user intent – without the guesswork and (more importantly) without having to stitch it together from fragments scattered across the page.
Practical application: Structure for extraction – clean H-hierarchies, headings as questions, immediate direct answers, HTML tables, markdown bullet points, numbered steps, exact key-value pairs, and minimal-to-no marketing fluff.
For ChatGPT, content that extracts well beats content that reads well – every day.
Full decision-arc coverage
ChatGPT has long ceased to be a mere chatbot. Today, it permeates virtually every stage of the B2B buyer journey, from vendor research to shortlisting to training for sales negotiations. It’s a veritable decision-making platform that covers full decision arcs and, thanks to fanout + RRF mechanics, it does it unprompted. To rank higher in ChatGPT, you should, too.
Practical application: Create content clusters that cover different angles of the decision journey – pages addressing what your product/service does, who it’s best for, why it works, how it works, how it compares to other products/services (including competitors’), and what users say. Be sure to interlink them tightly using descriptive, unambiguous anchors to help ChatGPT crawlers map your topical authority.
Covering the full decision arc effectively forces your brand into multiple parallel search pools, maximizing your final RRF score – and selectability
A word of caution: Do NOT manufacture flimsy, watered-down pages just to cover every query fanout. Per Google’s spam guidelines, this practice falls under scaled content abuse, and it works against you on every platform and every engine.
Third-party validation
A study by BrightEdge found that ChatGPT cites community threads right alongside elite, high-authority editorial and reference sites roughly 36% of the time for complex and informational queries. This is not a fun factoid, but a critical insight on how to do SEO for Chat GPT: community consensus is a structural foundation for truth not informal social commentary.
The reason for this behavior is fourfold:
Algorithmic aggregation: ChatGPT’s underlying search engine prioritizes high-authority, heavily-indexed sites, pulling its “facts” from the top-ranked results.
Next-token prediction: LLMs “parrot” what they see most frequently in high-quality contexts. A claim on your own site is an assertion. Corroborated by the community, it’s evidence.
Data curation: AI developers favor conversational, human-vetted data for next-model training, which is why community platforms bear disproportionate weight in synthesized answers.
Consequently, the optimization paradigm is now flipped upside-down: in the classic SEO era you optimized your brand; in the AI era you optimize the entire internet consensus of your brand.
If ChatGPT searches the web for your category, and your name only appears on your website, you’re not a potential citation source. You’re a statistical anomaly.
Practical application: Optimize the internet consensus of your brand – secure mentions in unsponsored Reddit threads and independent forums/communities, maintain robust profiles on review platforms like G2, Capterra, and Trustpilot, and build consistent sentiment and brand association across diverse, independent domains.
A word of caution:Astroturfing (inauthentic mentions) is increasingly discouraged. Review platforms have aggressive fraud-detection algorithms and AI platforms are being trained to filter them out, albeit with limited success. While inauthentic third party mentions are currently widespread, we expect this to change as AI platforms evolve. The safest route is to build up genuine authority through high quality content and citation work.
How to refine your ChatGPT optimization strategy?
Once you’ve set up a strong foundation using the previous steps, you can proceed with the following refinement strategies to further compound the advantage: prioritizing content typesthat ChatGPT favors, implementing structured data to sharpen entity clarity, and refreshing pages periodically to boost recency signals.
Prioritize content types ChatGPT favors
This is where how to optimize for search results in ChatGPT diverges from Perplexity and AI Overviews optimization strategy, as well as where the majority of popular advice gets the weighting wrong.
Platform-specific
What ChatGPT cites most
Product-page dominant — the opposite of the “listicles win everywhere” myth.
Product & service pagesDominant
Spec-rich, fact-dense pages — cited more than any other format.
ListiclesStrong 2nd
Close behind — pre-structured, easy to lift.
HomepagesNotable
Useful for entity clarity, but trailing.
Profile pagesTrailing
Far behind the leaders.
Category pagesTrailing
Far behind the leaders.
Ordinal ranking — relative citation frequency, not exact shareSource: ZeroClick citation study
The internet “consensus” is that “listicles win everywhere.” In the case of ChatGPT, this is not 100% true. Our research found that ChatGPT exhibits product-page dominant citation behavior, leaning on spec-rich, fact-dense pages more heavily than any other model. Listicles are a strong second, with homepages, profile pages, and category pages notable but trailing far behind.
Therefore, for ChatGPT specifically, treat product and service pages as fundamental citation assets. Make them factually dense, specification-rich, unambiguous, verifiable, self-contained, and free of marketing fluff.
Implement structured data to sharpen entity clarity
We’ve already established entity clarity as one of the core citation levers. Now, you can enhance it using structured data. Implementing Schema.org types (Organization, Article, FAQPage) adds a “translation layer” that reduces ambiguity about who you are, what you do, and who you cater to – which is exactly what selection algorithms reward.
However, do not make the mistake of thinking of Schema as a citation magnet or a substitute for content quality. Despite what persistent structured data myths say, Schema is not a fast track to AI citations and definitely not a replacement for quality. What it is is a way to reinforce those signals, thereby sharpening entity clarity that feeds the selection mechanism.
Refresh your content to boost recency signals
ChatGPT is trained to deliver current context, which is why it tends to favor fresh content. This is especially true for time-sensitive queries, meaning that a “how to rank in ChatGPT” guide from 2026 will always beat a 2024 one, for example.
As such, it pays to update your pages quarterly – not just to increase your odds for ChatGPT citation, but because recency is a top-tier trust signal. However, simple date or cosmetic changes won’t do. ChatGPT is smarter than that, so these revisions must be substantive.
In addition, you don’t have to update your entire content library. In fact, that’s the wrong approach. Instead, prioritize pages that are already earning citations, where lift comes fastest and resource spend is minimal.
The paradigm shift
Old SEO vs new AI SEO
You no longer optimize your domain — you optimize the web’s consensus about your brand.
Old SEO strategy
New AI SEO strategy
Publish keyword-optimized blogs on your own domain.
Secure mentions in unsponsored Reddit threads and third-party listicles.
Optimize for Google’s spiders to crawl your site.
Maintain robust, highly rated profiles on G2, Capterra, and Trustpilot.
Build backlink volume.
Build consistent sentiment and brand association across independent domains.
~36%ChatGPT cites community threads alongside elite editorial and reference sites this often on complex, informational queries.
Quick referenceSource: BrightEdge; ZeroClick Labs
How to optimize for ChatGPT past 2026?
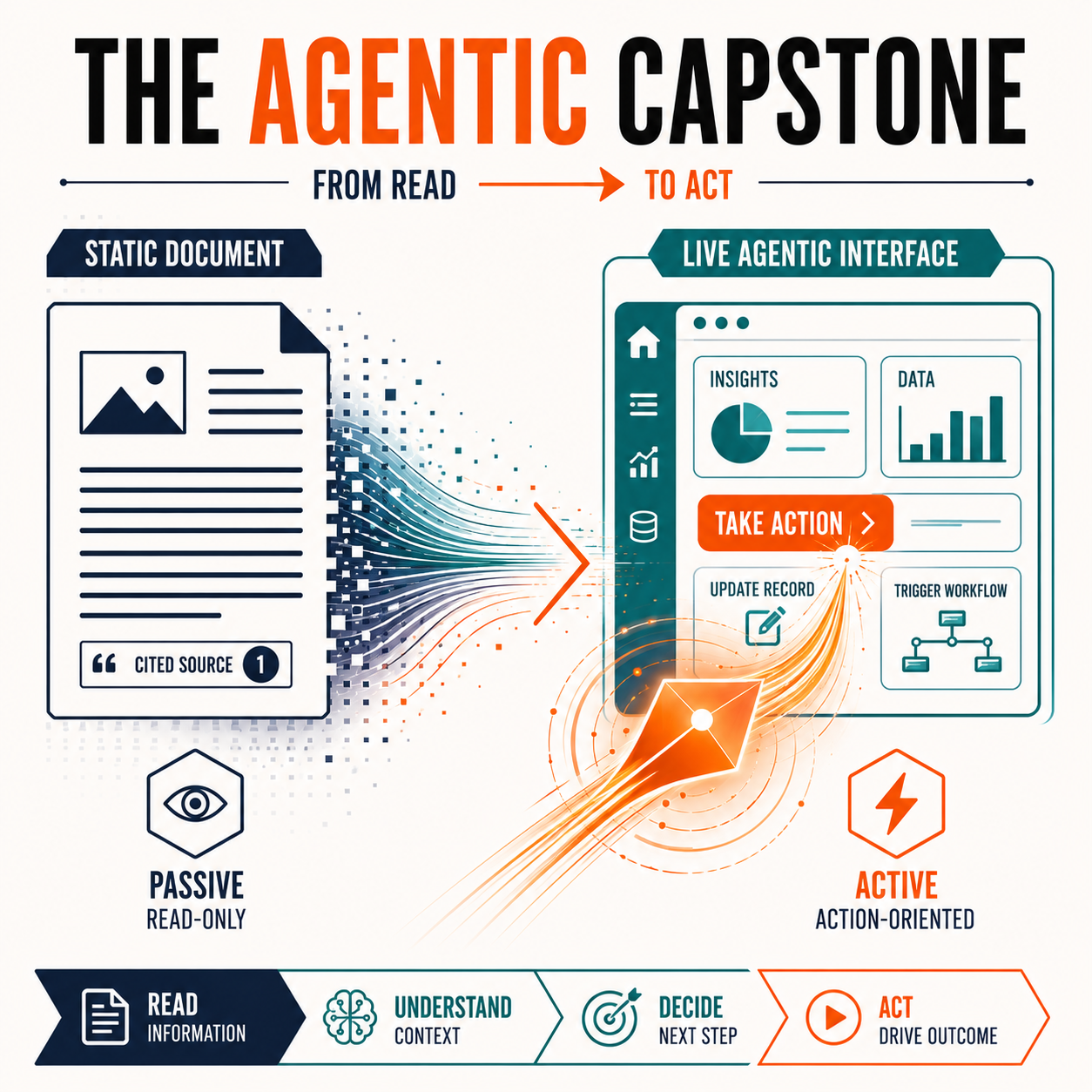
Search is rapidly becoming agentic, and OpenAI isn’t lagging behind. ChatGPT Agent can already complete complex, multi-step tasks on the user’s behalf, and although the technology is at a starting point, the endpoint is clear: it’s not just about being citable, but being operable.
Past 2026, winning brands will be those who provide a surface for autonomous agents to act on, not merely read.
The good news is that, by following the above optimization steps, you’re already laying the practical groundwork for this major shift, specifically by including clean static HTML, stable layout, machine-readable content, and forms that don’t fight automatic access.
Even better news is that all these efforts compound: virtually every investment in citation visibility makes your brand easier for AI agents to operate, meaning that the work isn’t obsoleted by the shift. Quite the contrary – it’s amplified by it.
Being citable isn’t the same as being operable – but optimizing for the former sets the foundation for the latter. [Image credit: ZeroClick Labs via ChatGPT]
Seth Matthews, an AI SEO content writer within ZeroClick Labs, began his career in civil engineering, but his passion for writing drove his deliberate transition into professional content strategy and SEO. The clash of two worlds produced a writer who can effortlessly combine technical precision and narrative clarity with the emotional and psychological impact of creative storytelling.
ChatGPT visibility is won deliberately, or not at all
Ranking earned the click. Citation earns business.
Traffic ChatGPT sends your way is more valuable than 100 clicks, exactly because buyers arrive pre-informed and pre-determined to do business.
ZeroClick Labs is here to help you capture that traffic.
Rely on us to align your brand, content, and website with ChatGPT’s selection mechanics, so when the time comes for your buyer to get their answer – you are on top of the recommendation stack.
Connect with us today, and let’s make your brand win ChatGPT!
“Our agency had no idea how to approach AI visibility. ZeroClick only does this one thing so they actually know what works. Worth every penny just to not waste time figuring it out ourselves.” – Jay